
声明式多智能体协同:基于 Claude Agent SDK 构建深度研究系统
摘要总结:对复杂研究任务时,单智能体(Single-Agent)常因上下文稀释和逻辑疲劳导致产出质量下降。本文基于 Claude Agent SDK 探讨了多智能体系统(MAS)的工程化落地。通过 “Lead + Subagent” 的声明式架构,我们将深度研究拆解为搜索、量化分析、可视化绘图与结构化写作四个独立环节。 实践证明,通过严格的职责隔离(如 Lead Agent 仅负责调度)与工程边界约束(如 Researcher 强制提取量化指标),MAS 能够生成具备专业数据图表支撑的深度报告。本文将从架构设计、工作流编排到 PDF 自动生成,完整还原这一“AI 驱动调研流水线”的构建过程,并展示其在教育研究案例中的实战效果。
1. 引言
在 AI Agent 深度全景综述一文中,我们探讨了多智能体系统(Multi-Agent Systems, MAS)的理论优势。从理论层面看,这类系统通过任务分解、职责隔离与并行协作机制,有效突破了单智能体在复杂任务中的能力瓶颈——不仅显著提升了任务处理的天花板,更通过模块化的设计增强了系统的可解释性与可控性。
但在实际工程落地中,开发者往往会面临一个尴尬的现实:简单的任务单智能体就能搞定,复杂的任务给单智能体加再多 Prompt 也会陷入“逻辑疲劳”或“上下文迷失”。深度研究(Deep Research)正是这类复杂任务的典型代表。它要求系统在长上下文环境下,同时具备高效的信息检索、严谨的数据推理和专业的文档输出能力。
本文将分享我基于 Claude Agent SDK(TypeScript 版)构建 Deep Research Agent 的实践过程。我们将探讨如何通过声明式架构实现多 Agent 的职责隔离,并展示这种模式如何通过模块化设计显著提升研究报告的专业度。
说明:
- 本项目基于 Anthropic 官方示例进行了 TypeScript 重构与流程优化。完整代码已开源至 GitHub,托管在我与几位好友共同创建的 full-stack-workspace 组织下的 agent-playground 仓库中,具体路径为:@agent-playground/deepresearch-agent。
- 如果你希望了解 Python 版本的实现,建议直接查阅官方示例仓库:claude-agent-sdk-demos
2. 为什么深度研究需要 Multi-Agent 架构模式?
回顾我们自己在某个领域或专题进行深度研究的经历,不难发现:深度研究并非单一的写作任务,而是一个多工种流水线。这其实是一个典型的多阶段任务,每个阶段都需要不同的专业能力:
| 阶段 | 描述 |
|---|---|
| 搜索阶段 | 专注于信息检索与收集,帮助建立对该领域的初步认知 |
| 分析阶段 | 对收集到的信息进行深度分析与归纳,提取关键洞察,并据此确定研究方向与重点 |
| 写作阶段 | 将分析成果转化为结构化的文字内容,如研究论文、技术报告等 |
| 可视化阶段 | 通过数据图表、信息图等形式直观呈现分析结果,提升信息传达效率 |
这种阶段化的专业分工,与人类研究团队中的协作模式高度契合。此外,深度研究任务往往涉及很多信息整合,具有较高的复杂度。若采用单智能体架构,通常会面临 Context Window 限制、早期信息被稀释、推理质量随任务推进而下降等挑战。
Multi-Agent 模式则通过任务分解、职责隔离与并行协作机制,有效突破了单智能体在复杂任务中的能力瓶颈——不仅能显著提升任务处理的上限,更通过模块化设计增强了系统的可解释性与可控性。
3. 系统架构
3.1 核心设计与职责分配
DeepResearch Agent 通过搜索、收集、分析各种来源的信息,将这些信息整合为带有可视化图表的深度研究报告,以支持复杂的研究和决策任务。其架构采用 Lead Agent + Subagent的设计思路:
- Lead Agent 的核心规则是“只做管理,不做执行”。它的 allowedTools 被严格限制为 Task 工具。这种设计能有效防止 Lead Agent 因为过度处理细节而导致的逻辑发散。
- Researcher 须找到 10-15+ 个具体数据点(百分比、市场规模、增长率等)供 Data Analyst 可视化
- Report Writer 使用 Python + reportlab 通过 Bash 工具生成 PDF 报告,确保报告格式专业、内容
| 智能体 | 职责 | 工具 |
|---|---|---|
| Lead Agent | 协调研究,并将任务委派给子智能体。任务分解、协调调度(仅使用 Task 工具委托任务) | Task |
| Researcher | 并行网络搜索,收集量化数据(每个研究员专注一个子主题) | WebSearch, Write |
| Data Analyst | 读取研究笔记,提取指标,生成 Python/matplotlib 图表 | Glob, Read, Grep, Bash, Write, Edit |
| Report Writer | 读取研究笔记和图表,生成 reportlab PDF 报告 | Skill, Write, Glob, Read, Bash |
Claude Agent SDK 起源于 Anthropic 的 Claude Code 项目,采用了与 Claude Code 相同的声明式设计,支持自定义技能和命令,针对 DeepResearch Agent 的具体任务,我们可以利用其声明式和模块化设计,添加一些相关的自定义 Agent Skills 和 Commands 命令:
deepresearch-agent/
├── .claude/
│ ├── skills/ # 可使用的 Agent Skills 技能目录
│ │ ├── pdf/ # 生成 PDF 报告的技能
│ │ └── executive-briefing/ # 生成摘要的技能
│ ├── commands # 可使用的 Agent Commands 命令目录
│ │ ├── market-trends.md # 市场趋势分析命令
│ │ ├── fact-check.md # 事实核查命令
│ │ ├── ...
│ │ └── competitive-analysis.md # 竞争分析命令3.2 工作流设计
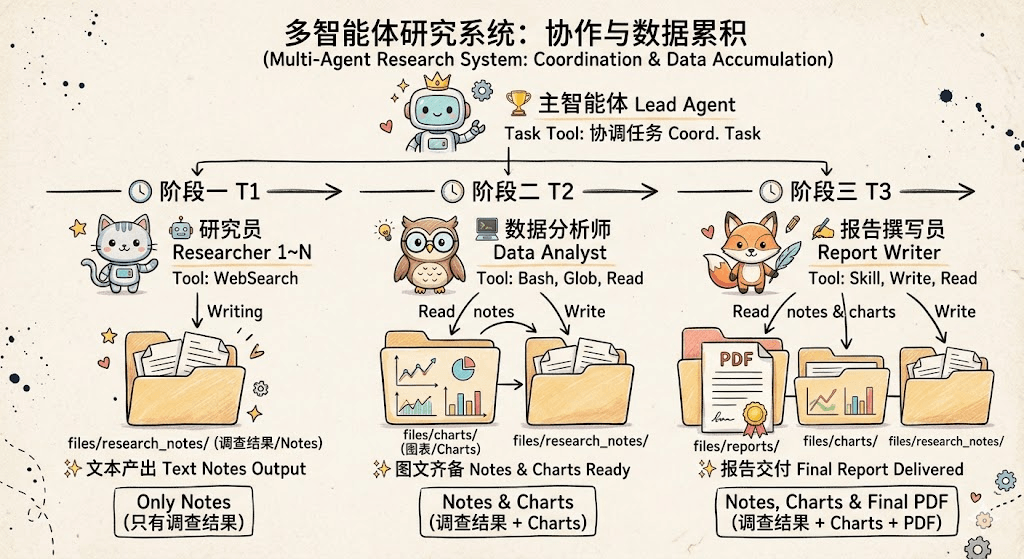
说明:
| 智能体 | 输出 | 说明 |
|---|---|---|
| ① 主智能体 Lead Agent | 任务分解 | 将用户请求分解为 3-5 个子主题 |
| ② 研究员 Researcher | research_notes/ | 并行网络搜索,收集调查成果 |
| ③ 数据分析师 Data Analyst | charts/ | 从研究结果提取指标,生成可视化图表 |
| ④ 报告撰写员 Report Writer | reports/ | 结合调查研究 + 图表,生成 PDF 报告 |
用户输入研究主题
│
▼
┌─────────────────────────────────────────────────────────┐
│ Lead Agent (协调者) │
│ - 将主题分解为 2-4 个子主题 │
│ - 并行生成 Researcher 子智能体 │
│ - 等待所有 Researcher 完成 │
│ - 生成 Data Analyst 子智能体 → 生成图表 │
│ - 生成 Report Writer 子智能体 → 生成 PDF 报告 │
└─────────────────────────────────────────────────────────┘
│
▼
PDF 报告 (files/reports/)输出目录:
| 目录 | 内容 | 由谁生成 |
|---|---|---|
files/research_notes/ | 研究员收集的量化数据(Markdown) | Researcher |
files/data/ | 数据摘要和分析结果 | Data Analyst |
files/charts/ | Python/matplotlib 生成的可视化图表(PNG) | Data Analyst |
files/reports/ | 最终 PDF 报告(嵌入图表) | Report Writer |
3.3 技术要点说明
| 要点项 | 备注说明 |
|---|---|
| Lead Agent 核心规则 | • 仅使用 Task 工具:Lead Agent 的 allowedTools 仅包含 ["Task"],不直接使用其他工具 • 并行委托:多个 Researcher 同时运行,而非顺序执行 • 严格顺序:所有 Researcher 完成 → Data Analyst → Report Writer |
| 研究员的数据优先策略 | • 使用 WebSearch 5-10 次进行数据聚焦查询 • 优先收集量化数据:市场规模、增长率、百分比、排名、对比数据 • 每个研究笔记必须包含 10-15+ 个具体数字 • 使用表格整理对比数据 |
| 图表生成 | Data Analyst 通过 Bash 执行 Python 脚本: • 使用 matplotlib/seaborn 生成图表 • 输出 2-4 个 PNG 图表到 files/charts/ • 同时生成 files/data/data_summary.md 作为数据摘要 |
| PDF 报告生成 | Report Writer: • 读取 files/research_notes/、files/data/、files/charts/ • 使用 pdf skill 获取 reportlab 指导 • 通过 Bash 执行 Python + reportlab 生成 PDF • PDF 包含:标题、执行摘要、关键发现、图表、来源 |
4. 实践案例:以“初中数学学习研究”为例
为验证系统的实际效果,我设定了一个具体的研究课题进行测试。在这个案例中,系统的输出展现出了令人惊喜的"产品化质感"。
4.1 执行流观察
主智能体将课题分解为“资源分布”、“重点模块”、“学习策略”等子任务,研究员们并行深入互联网寻找具体数字(如:各模块分值占比、记忆曲线数据)。
在研究完成后,我们在 files/ 目录下找到了以下输出结果:
deepresearch-agent/
├── files # 输出文件目录
│ ├── charts # 可视化数据分析产出的图表
│ │ ├── xxx.png
│ │ └── ...png
│ ├── data # 数据分析摘要总结
│ │ └── data_summary.md
│ ├── reports # 研究报告产出
│ │ ├── 初中数学学习指南.html
│ │ └── 初中数学学习指南_report_20260328.pdf
│ └── research_notes # 研究笔记产出
│ ├── 初中数学学习资源研究笔记.md
│ ├── 初中数学重点知识模块与学习策略.md
│ ├── 初中数学高效学习方法研究.md
│ └── 初中生数学学习问题与解决方法.md4.2 数据可视化的深度
在这种多智能体合作的场景下,每个智能体都有自己的任务和职责,最显著的提升还是在于 Data Analyst 的表现。由于它接收的是经过 Researcher 筛选后的量化笔记,生成的图表不仅准确,而且具备极强的说服力,甚至让人眼前一亮:
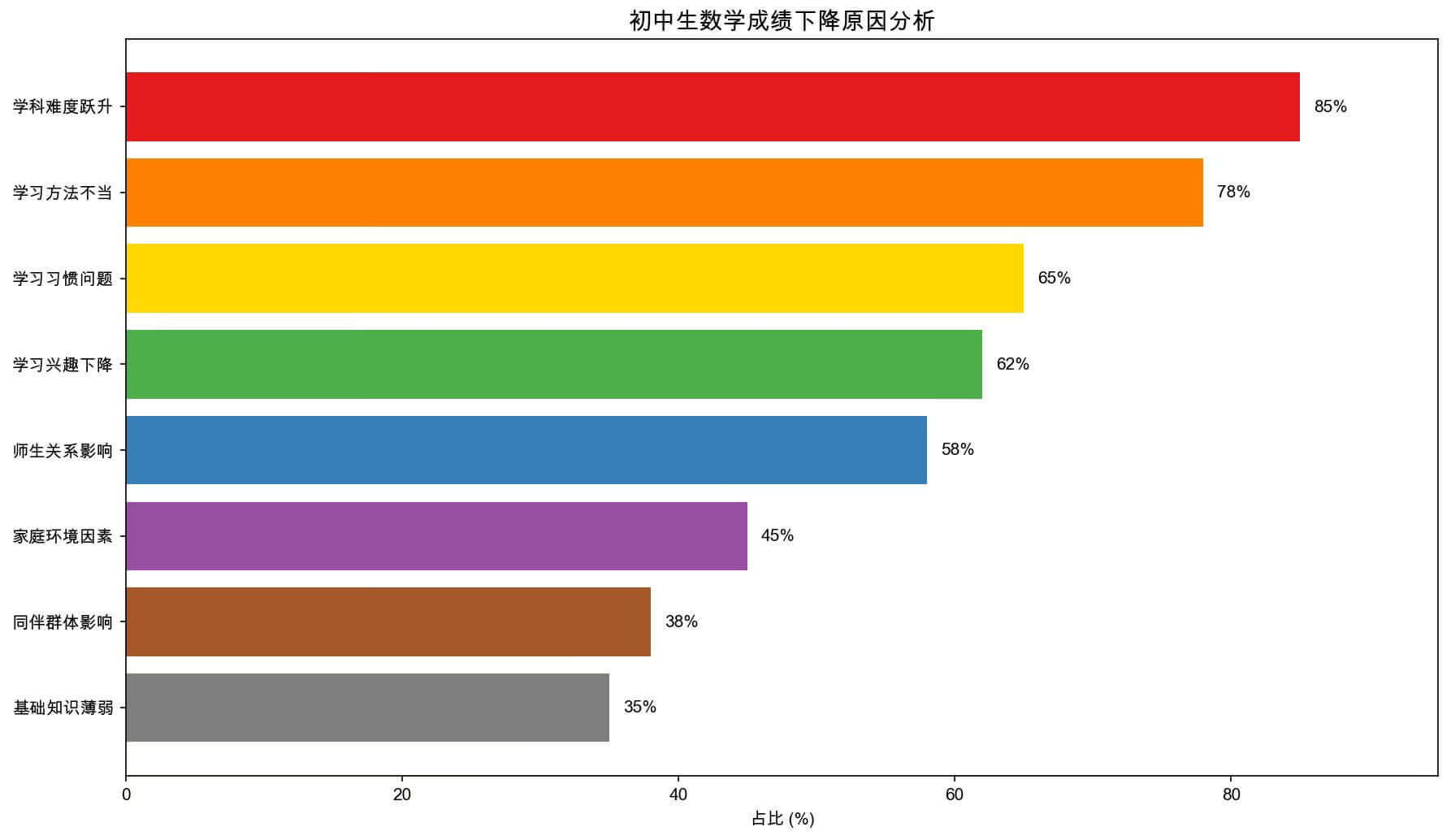
图 1:初中生数学成绩下降原因分析
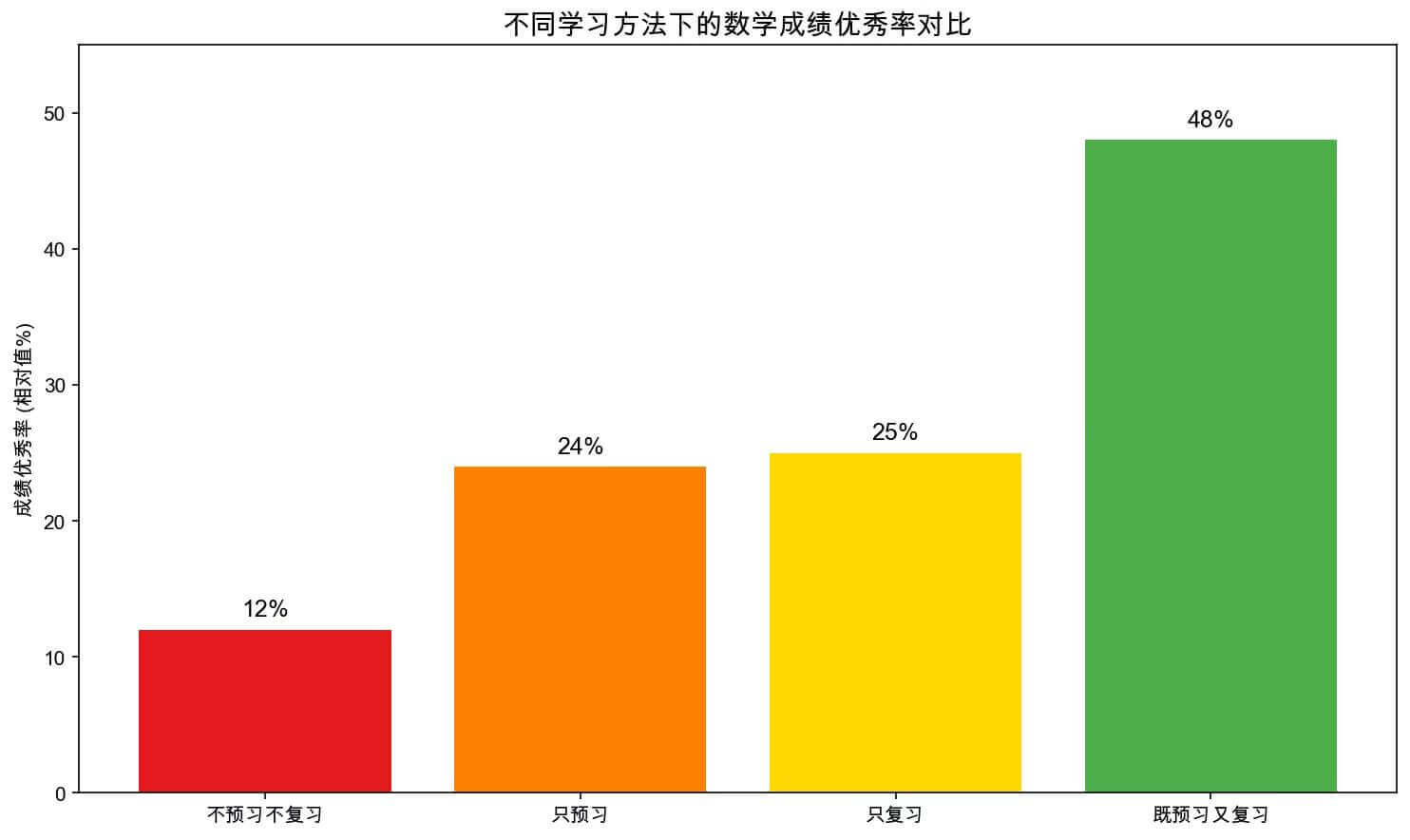
图 2:不同学习方法下的数学成绩优秀率对比
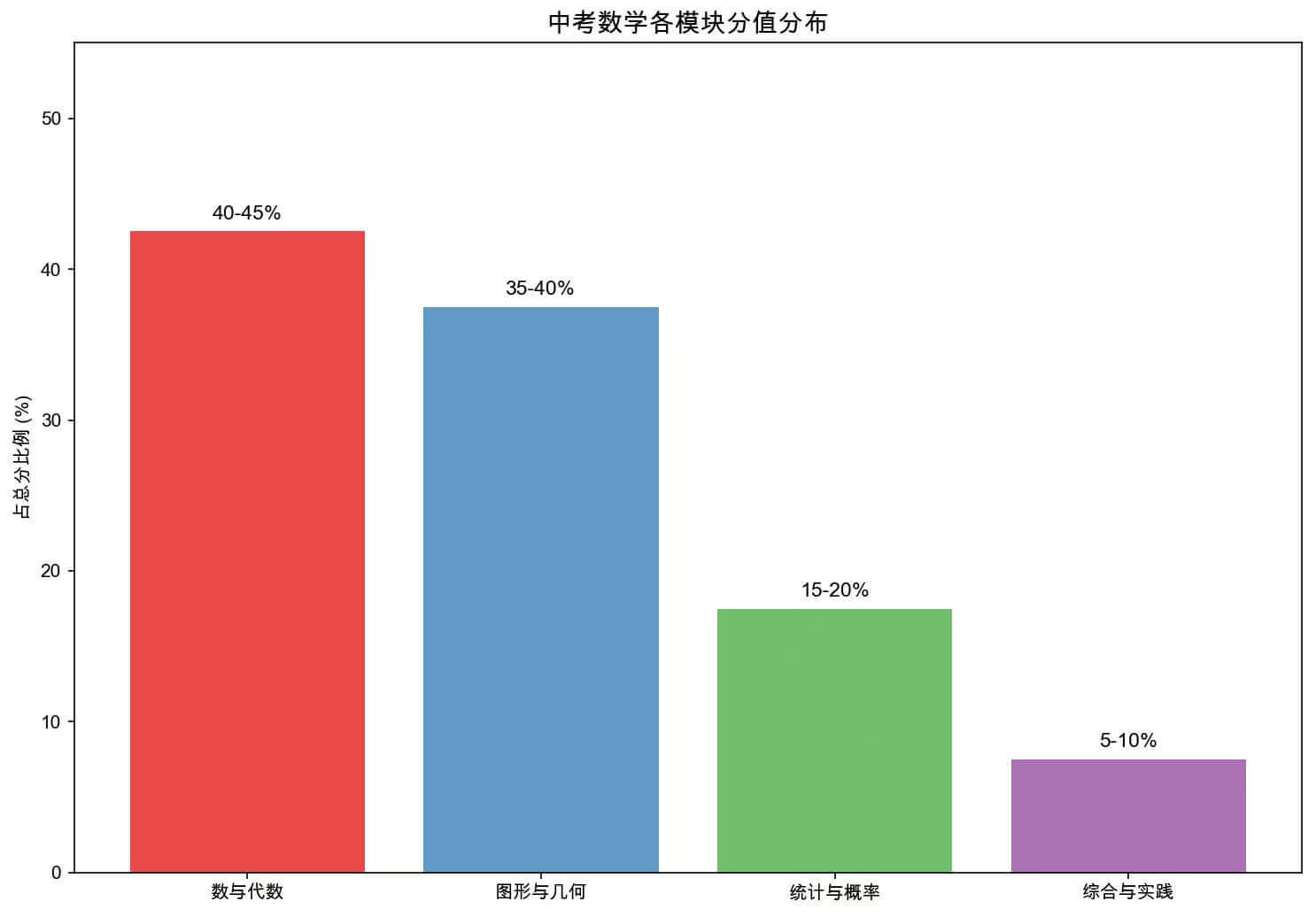
图 3:初中数学各模块分值占比分布示意
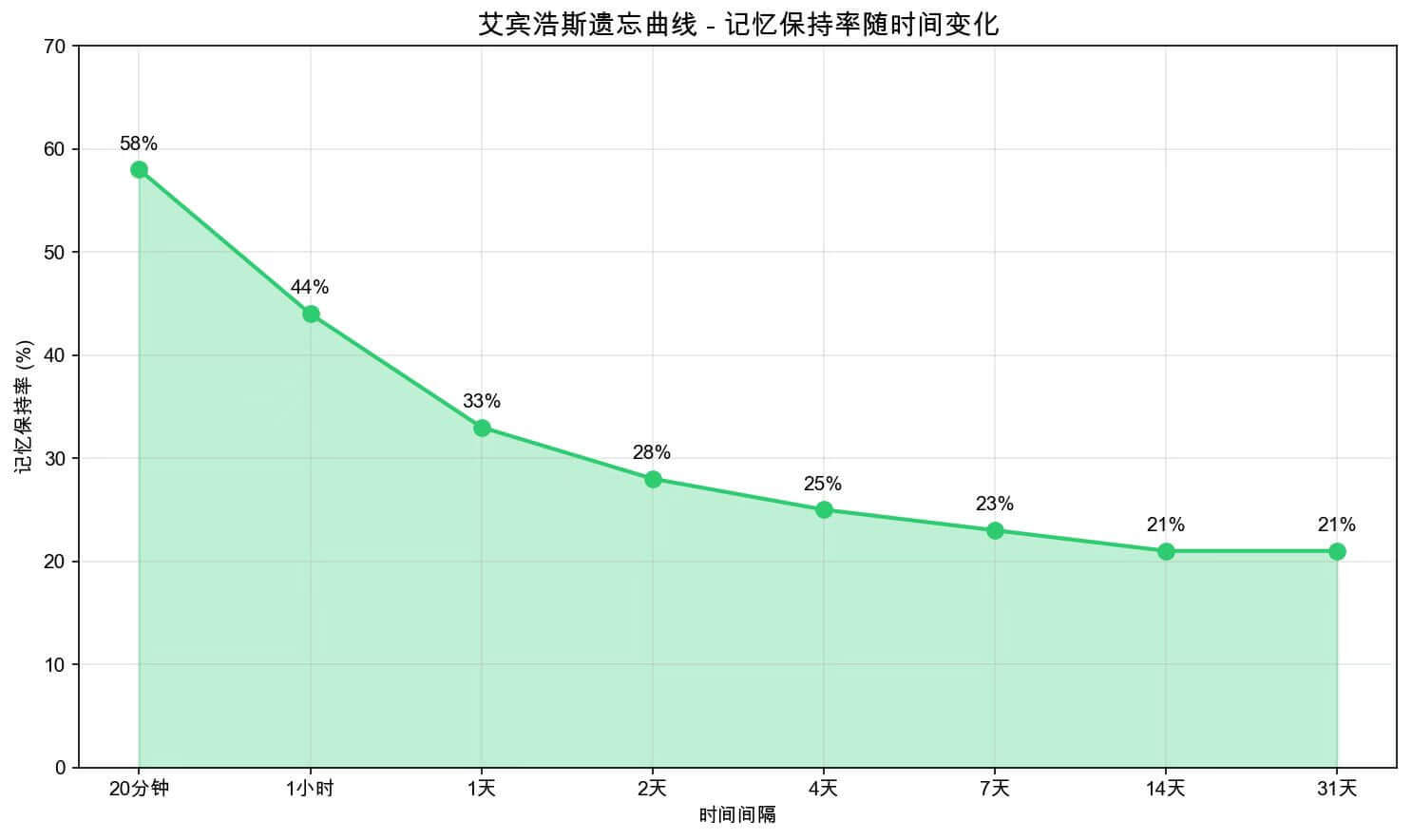
图 4:人的记忆保持随时间变化趋势曲线
这些图表并非简单的占位符,而是基于真实抓取的数据生成的专业资产。这种 “研究笔记 -> 量化提取 -> 代码绘图” 的链路,是单 Agent 架构难以企及的。
5. 结束语:迈向更可控的 Agent 开发
通过 Deep Research Agent 的实践,我们可以得出一个关键结论:Agent 的能力边界不仅取决于模型本身,更取决于开发者构建的工程约束。
Claude Agent SDK 提供的声明式开发体验,让我们能够像编写后端服务一样,为每个 Agent 定义清晰的接口和职责。这种“工程化”的思维,正是我们将 AI 从“对话玩具”转化为“生产力工具”的必经之路。
目前系统在多轮迭代(Refinement)机制上仍有提升空间。未来我们将探索如何引入一个“校对 Agent”来对生成的 PDF 报告进行自动评审,进一步闭环质量管理流程,这也是智能化博客运营过程中需要考虑的一个重要方面。