
如何编写一个高可用的 Agent Skill?从机制拆解到生产实践指南
摘要总结:大语言模型在特定工程领域常面临“知而不行”的困境。本文深度拆解 Anthropic 最新推出的 Agent Skills 规范,揭秘其如何通过渐进式披露与三级加载机制,在控制 Token 成本的同时显著提升 Agent 的任务执行精度。文章涵盖了从文件夹架构设计到实战 git-workflow 编写的全流程指南,助你将零散的 Prompt 转化为标准化的数字资产。
1. 引言:Agent Skills 是什么?
在大语言模型(LLM)的落地实践中,开发者经常面临一个共性挑战:模型在特定细分领域往往处于“知而不行”的状态——虽然拥有博杂的知识,却缺乏执行复杂任务的专业路径。
为了解决这一痛点,Anthropic 在其旗舰模型 Claude 3.7 系列中正式推出了 Claude Skills。这一功能将 LLM 的能力封装为直观的“能力文件夹”,极大提升了智能体的实用性,并迅速在开发者社区引发热议。2025 年 12 月,随着 Anthropic 联合生态伙伴正式开源 Agent Skills 规范,Agent Skills 的标准化也正式开启(而这一能力最直接、最硬核的落地载体,便是其配套的命令行工具 Claude Code)。
我们可以从两个维度来理解 Agent Skills 是什么:
| 维度 | 说明 |
|---|---|
| 工程架构维度 | Agent Skills 是一种模块化的能力组件,用于更优雅地扩展 AI 智能体(Agent)的功能,让 Agent 能够在更复杂的场景下执行更专业的任务。 |
| 实现维度 | 它是一个包含完整指令说明、配套脚本和资源文件的能力文件夹,集成了完备的指令说明(Prompts)、配套脚本(Scripts)及相关资源文件,其核心精髓在于:渐进式披露、动态发现与按需执行,从而在扩展能力的同时,严格控制上下文窗口的 Token 消耗和认知过载。 |
在 构建 Agentic 生态:零散组件化为可持续的工作流 一文中,我们确立了一些 “可持续工作流” 的共识。接下来,我们将通过细节解析与工程实践,揭开 Agent Skills 的面纱。
2. 文件夹结构拆解:标准化的操作手册
从本质上来讲,Agent Skills 是提供给 AI 的“操作手册 + 资源包”,其标准化的目录树如下:
严格的工程规范:
- 主文件必须命名为
SKILL.md(区分大小写,不能有其他变体)。- 文件夹名称必须使用 kebab-case(如
my-skill-name,不能写成My Skill Name)。
skill-name/
├── SKILL.md ← 主文件(必需):SKILL描述、逻辑编排、核心指令,是技能核心内容。
├── scripts/ ← 脚本(可选):Python、Bash 等脚本, 是可执行代码。
├── references/ ← 参考资源(可选):规则、规范、参考指南、示例等。
└── assets/ ← 可选素材附件(可选):模板、字体、图标等资源。- 核心文件 SKILL.md,由两部分组成:
- YAML 元数据 (Frontmatter):定义技能的基础属性,必须包含 name(唯一标识)和 description(核心作用及触发时机,需包含特定关键词以便 Agent 路由)。
- Markdown 指令:定义具体的执行逻辑、步骤与约束。
- 外围资源 (scripts/, references/, assets/ 等可选文件),遵循 “按需加载”原则:
- scripts/:包含 Agent 可以运行的可执行代码,一般为 Python、Bash 或 JavaScript 等脚本语言,类似于轻量级的 MCP,提供底层工具链支持。
- references/:包含 Agent 在需要时可查阅的其他文档,比如 UnitTestSpec.md、CodeSpec.md、ArchitectureSpec.md 等,保持各个文件的简洁性,Agent 按需加载。
- assets/:主要为一些包含静态资源的文件夹,比如文档模板、表格示例,静态图片等等。
目前,这套标准已被多个 AI 原生开发环境采纳(例如 Claude Code 存放在 .claude/skills/, OpenClaw 存放在 .openclaw/workspace/skills/)。
3. 核心机制与流程:渐进式披露的艺术

图 1:来自 Anthropic 官方文档
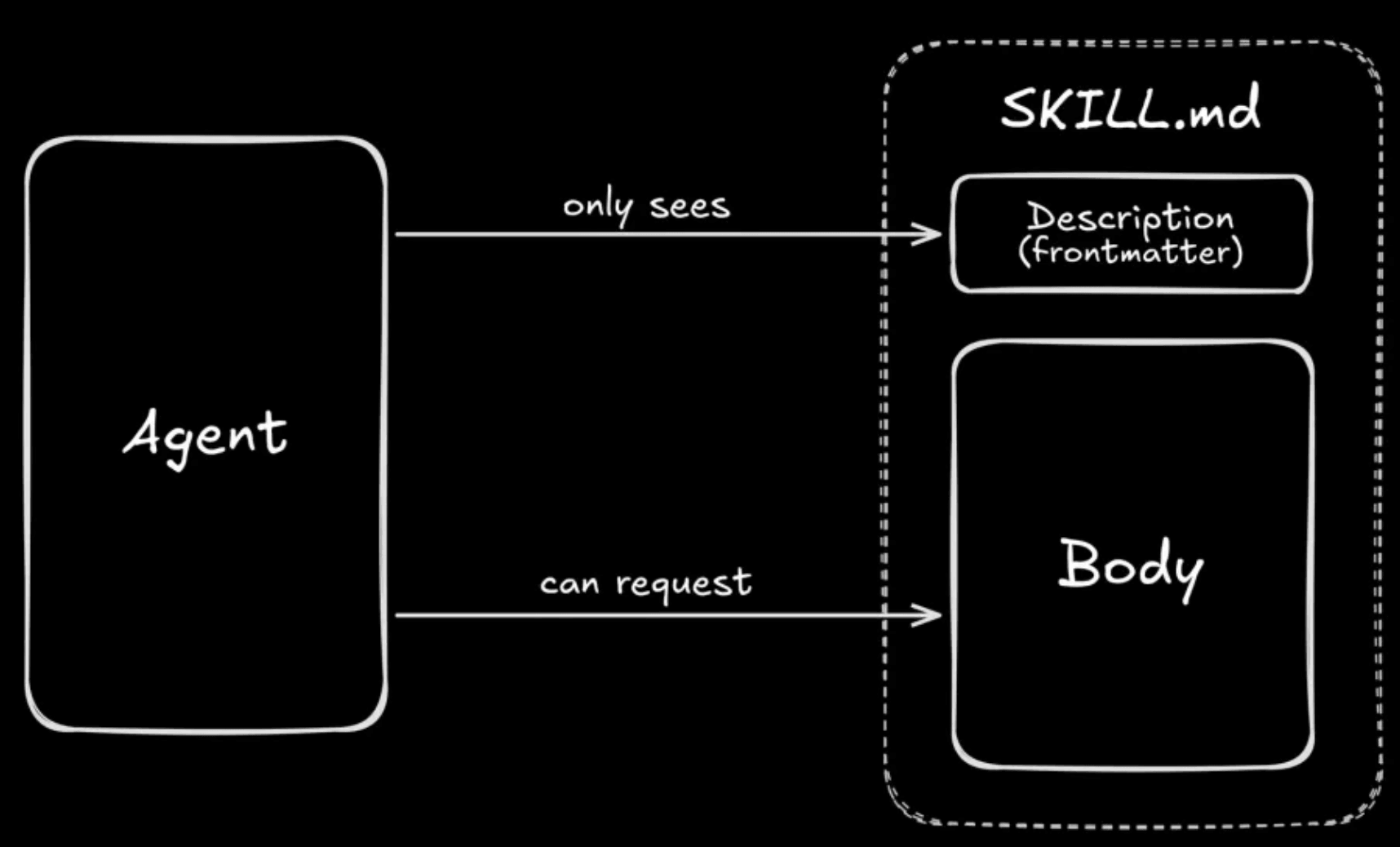
图 2:核心工作机制示意
所谓渐进式披露与动态发现,是指 Agent 最初只能看到技能的描述(Frontmatter),但可以在需要时再请求加载技能正文,采用智能的三级系统:
- Level 1(路由层— YAML 前置信息):仅将所有技能的 name 和 description 加载到 Agent 的 System Prompt 中,借此进行“意图识别”和技能路由。
- Level 2(指令层— SKILL.md 内容):只有当 Agent 判定某技能匹配当前任务时,才会读取该技能的完整指令正文。
- Level 3(资源层— scripts、references、assets):在执行具体步骤时,按需读取 references/ 中的外链规范,或调用 scripts/ 运行代码(仅将执行结果返回给 Agent,而非加载代码本身)。
Skill 本身不会直接让 Agent 更聪明,但它让信息更聚焦、更容易被检索。Agent 可以根据任务需求,动态加载不同的技能,这种机制比挂载庞大的全局上下文更轻量,极大降低了 Token 消耗成本,并显著提升了任务的成功率。
让我们再从一个更全景的角度来分析 Agent Skill 的工作流程:
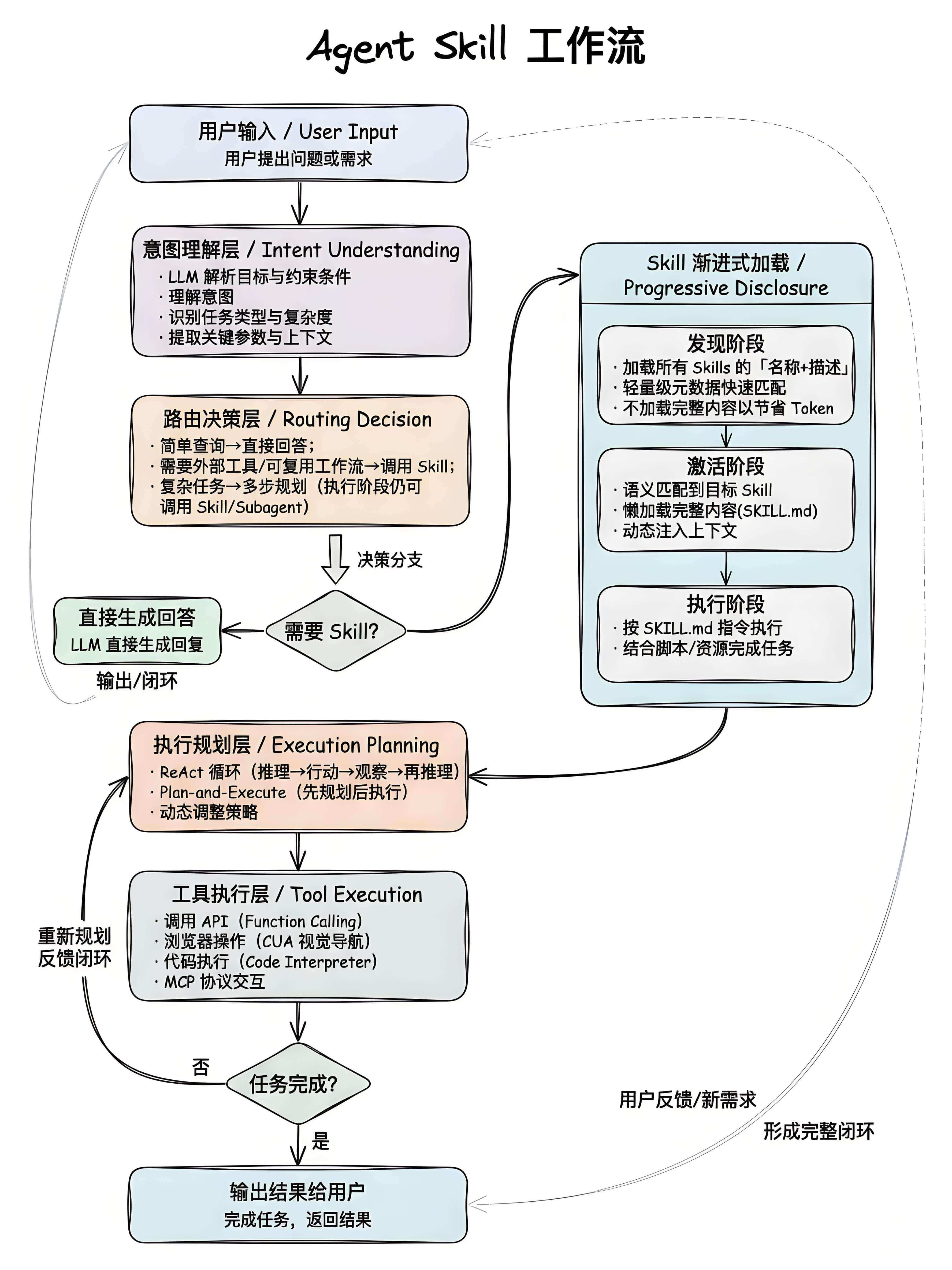
当 LLM 完成意图理解后,会在路由决策层进行判断,若任务属于特定专业领域(如代码重构、特定格式文档转换),系统将不再仅依赖通用模型能力,而是转向右侧的 Skill 渐进式加载模块。主要包括 3 个阶段:
| 阶段 | 操作 | 作用 |
|---|---|---|
| Level 1:发现阶段 (元数据匹配) | 仅检索 SKILL.md 中的 YAML 前置信息(name 和 description) | Agent 在此阶段只感知技能的存在与用途,用于快速确认该技能是否能解决当前意图,不加载具体指令 |
| Level 2:激活阶段 (懒加载正文) | 确认匹配后,Agent 才会读取 SKILL.md 中的 Markdown 指令数据 | 将具体的逻辑编排、核心指令注入当前上下文,Agent 此时才正式获取"如何执行"的详细指南 |
| Level 3:执行阶段 (资源挂载) | 根据指令需求,按需调用文件夹内的辅助资源:从 references/ 读取规范文档(如 CodeSpec.md),或执行 scripts/ 中的代码 | Agent 仅接收执行结果反馈,不读取脚本源码 |
4. 实践指南:如何写好一个 Agent Skill?
理解了机制,真正的挑战在于业务转化:如何将脑海中的研发规范或操作流程,翻译成高质量的 Skill?设计精良的 Skill 是提效利器,而设计糟糕的 Skill 则会成为 Agent 的思维负担。
一个设计良好的 Skill 能够显著提升 Agent 的执行效率和输出质量,而设计不当则可能成为负担。接下来,我们将从编写原则、具体步骤到检查清单,系统性地探讨如何写好一个 Agent Skill。
4.1 核心编写原则
| 优秀设设计(最佳实践) | 常见失败模式(反模式) |
|---|---|
| • 确保描述真正可「路由」,让 Agent 能精准匹配技能 • 定义文件 SKILL.md 要极简,作为快速上手指南,而非资料仓库 • 重内容外链,渐进式披露,保持上下文窗口干净 • 明确定义「完成」标准,减少歧义 | • 百科全书型:内容像 Wiki,未拆分为小文件按需加载 • 全都要型:如果一个技能适用于所有任务,那它就不是技能,而是规则或仓库约定 • 暗号型:如果 agent 从来不加载这个技能,说明描述太抽象,需要遵循设计原则修改; • 脆弱型:过于具体,硬编码细节过多,仓库一变就失效 |
4.2 四步法
步骤 1:明确使用场景与边界
在动手期之前,我们要先理清逻辑,搞清楚:希望完成什么目标?需要哪些多步骤流程?涉及哪些领域知识或工具?
使用场景:[具体的使用场景与边界]
触发条件:[用户说 “xxx”、处理 xxx 事务或流程环节时触发]
工作流:步骤1 → 步骤2 → ...
依赖项:需要用到哪些领域知识与规则,依赖哪些工具能实现
验收标准:[达到什么样的具体目标,产物是什么样子的?]步骤 2:编写元信息(YAML Frontmatter)
这是编写 Agent Skill 中最关键的部分,直接关系到 Skill 会不会被调用到。描述必须做到两点:
- 长度不超过 1024 个字符,禁止使用 XML
< >标签。 - 说明技能功能,并明确触发条件,需要包含真实的触发短语。。
---
name: your-skill-name
description: 它能做什么。当用户说 [具体短语] 时触发。
---
# ✅ 优秀设计 — 场景具体,包含真实触发短语
---
name: design-to-code
description: 分析 Figma 设计文件并生成前端组件与开发文档。当用户上传 .fig 文件,或提到“design specs”、“组件文档”、“UI 切图”时触发。
---
# ❌ 糟糕设计 — 过于模糊,无法触发
---
name: helper
description: 帮助处理前端开发项目。
---步骤 3:编写执行指令 (Markdown Body)
使用结构化的 Markdown 编写具体动作,替代模糊的形容词。
# 技能名称
## 指令说明
### 步骤 1: [操作]
具体、可执行的描述。不要写“验证数据”,而是写:
“运行 python scripts/validate.py --input {filename}”。
## 示例
用户说: "创建新项目"
1. 通过 MCP 获取现有项目
2. 使用提供参数创建新项目
结果: 项目创建完成,并提供确认链接
## 故障排查
- 错误: 连接被拒绝
- 动作: 提示用户检查 MCP 服务状态,或检查本地端口占用情况。步骤4:Skill 质量检查清单 (Checklist)
一个达到工程交付标准的 Skill,必须能经受住以下灵魂拷问:
- 触发条件(描述):Agent 清楚知道何时加载它吗?
- 前置输入:执行前,它知道向用户或代码库索要什么依赖信息吗?
- 执行流:操作步骤是否无歧义、可按序执行?
- 验证机制:如何用客观标准证明任务成功了?
- 熔断机制:什么情况下它应该停止尝试,转而向人类求助?
- 格式规范:Kebab-case 命名?没有 XML 标签?SKILL.md 严格匹配?
5. 一个具体的 Agent skill 示例:git-workflow
1、SKILL.md 文件示意如下:
---
name: git-workflow
description: 当需要进行 Git 操作(如创建分支、提交代码、同步仓库、解决冲突或准备 PR)时,请使用此技能。涉及关键词:"git", "commit", "branch", "push", "pull request", "rebase", "merge"。
---
本技能旨在确保仓库的提交历史清晰、分支管理规范,并符合工程化流水线(CI/CD)的触发要求。
## 1. 分支命名规范 (Branching Strategy)
在执行 `git checkout -b` 前,必须遵循以下前缀:
- `feat/` : 新功能开发 (例如: `feat/user-auth`)
- `fix/` : 修复 Bug
- `docs/` : 文档变更
- `refactor/` : 代码重构(不影响功能的改动)
- `chore/` : 构建过程或辅助工具的变动
## 2. 提交规范 (Commit Message)
必须遵循 **Conventional Commits** 格式。在执行 `git commit` 前,请参考 `references/commit-spec.md`。
**基本格式:**
`<type>(<scope>): <description>`
**示例:**
- `feat(core): 接入身份验证中间件`
- `fix(ui): 修复移动端导航栏遮挡问题`
## 3. 核心工作流 (Workflow Steps)
1. **同步基准**:在开始开发前,确保从 `main` 分支拉取最新代码并执行 `rebase`,而非 `merge`。
2. **变更原子化**:保持每个 Commit 的改动是原子的,不要在一个提交中混杂无关的代码改动。
3. **前置校验**:在提交前,必须运行本地校验逻辑(如 `pnpm lint` 或 `pnpm test`)。
4. **清理历史**:在推送(Push)前,如有多余的“WIP”提交,请使用 `git rebase -i` 进行合并。
## 4. 冲突处理 (Conflict Resolution)
遇到冲突时,Agent 应:
1. 停止当前操作并列出冲突文件。
2. 分析冲突产生的原因(是由于基准过旧还是多人同时修改同一逻辑)。
3. 向用户建议保留方案,获得确认后再执行 `git add` 和 `git rebase --continue`。
## 5. 成功验收标准 (Success Criteria)
- [ ] 分支名符合前缀规范。
- [ ] 所有提交信息均能通过 `commitlint` 校验。
- [ ] 提交历史中没有空的或重复的合并记录。
- [ ] 本地 Lint 和单元测试全部通过。
参考规范文件:references/commit-spec.md2、references/commit-spec.md 文件示意如下:
# 详细提交规范 (Detailed Commit Spec)
为了保证 `CHANGELOG.md` 的自动化生成,请严格遵守以下 Type 定义:
| Type | 说明 |
| :--- | :--- |
| **feat** | 新功能 (feature) |
| **fix** | 修补 Bug |
| **docs** | 文档 (documentation) |
| **style** | 格式 (不影响代码运行的变动) |
| **refactor** | 重构 (既不是新增功能,也不是修改 Bug 的代码变动) |
| **test** | 增加测试 |
| **chore** | 构建过程或辅助工具的变动 |
| **revert** | 回退之前的 Commit |
## 范围 (Scope)
Scope 应该是描述改动受影响的模块名(如:`auth`, `api`, `sidebar`)。如果是 Monorepo 仓库,Scope 必须是对应的 package 名称。
## 描述 (Subject)
- 使用祈使句,首字母小写,结尾不加句号。
- 中文描述应简明扼要。6. 三类常见 Agent Skill 模式
在实际工程中,我们通常会遇到以下三种常见的 Agent Skill 模式:
模式 1:文档与资源生成
用于统一输出规范,避免大模型自由发挥导致的格式混乱。无需外部工具,仅通过内嵌模板和检查表即可实现。
- 场景:生成 PR 描述、架构设计文档、测试用例等。
- 参考:Anthropic 官方技能库中的
frontend-design、docx、pptx、xlsx等技能。
模式 2:工作流自动化
用于将人类的 SOP(标准作业程序)转化为 AI 可执行的 Pipeline。
- 场景:版本发布引导、新项目脚手架初始化。
- 参考:官方 skill-creator 技能——通过交互式引导,帮助用户一步步构建新的 Skill。
模式 3:MCP 增强与编排
将底层零散的工具 (MCP Tools) 串联成高可靠性的业务流,并补充领域知识和错误处理机制。
- 场景:自动化 Bug 修复、跨系统联动。
- 参考:Sentry 的 sentry-code-review 技能——将 Sentry 的错误日志获取工具与 GitHub 的代码审查工具结合,自动分析并修复 PR 中的 Bug。
7. 总结:从零散指令到可持续工作流
Agent Skills 的出现,标志着大模型应用开发正在走向真正的“面向工作流编排”。通过将散落的 Prompt、杂乱的脚本和抽象的领域规范统一封装到 SKILL.md 中,我们不仅为 Agent 建立了一条通往专业领域的“快速通道”,更为团队沉淀了一笔可以版本控制、可复用、可测试的数字资产。掌握 Agent Skills 的编写,是构建可靠、可预期 AI 应用的必经之路。
更多拓展阅读: