
重构开发者:AI 时代下的工程师能力图谱与演进指南
摘要总结:当 AI 极速降低代码编写门槛,单纯的“业务代码翻译器”角色正加速贬值。本文从技术演进与产品思考的交汇点出发,将 AI 时代的开发者能力图谱重新划分为三大核心圈层:产品应用层(Insight Stack)、Agent 开发层与 AI 基础设施层。无论你是深耕视图层交互、精通 Node.js 等服务端架构的开发者,还是致力于技术落地的探索者,都能在这份演进指南中找到打破能力边界、向“超级个体”与“AI 智能体指挥官”跃迁的破局之道。
如果你对近两年的技术浪潮保持敏感,大概会得出一个有些残酷但无比真实的结论:代码正在发生“通货膨胀”。随着大模型编程能力的指数级跃升,纯粹的“将业务逻辑翻译成代码”这项技能的溢价正在快速衰减。当 AI 能在几秒钟内吐出包含完整类型定义、错误处理和测试用例的后端接口或是 React 组件时,软件工程师的护城河究竟在哪里?
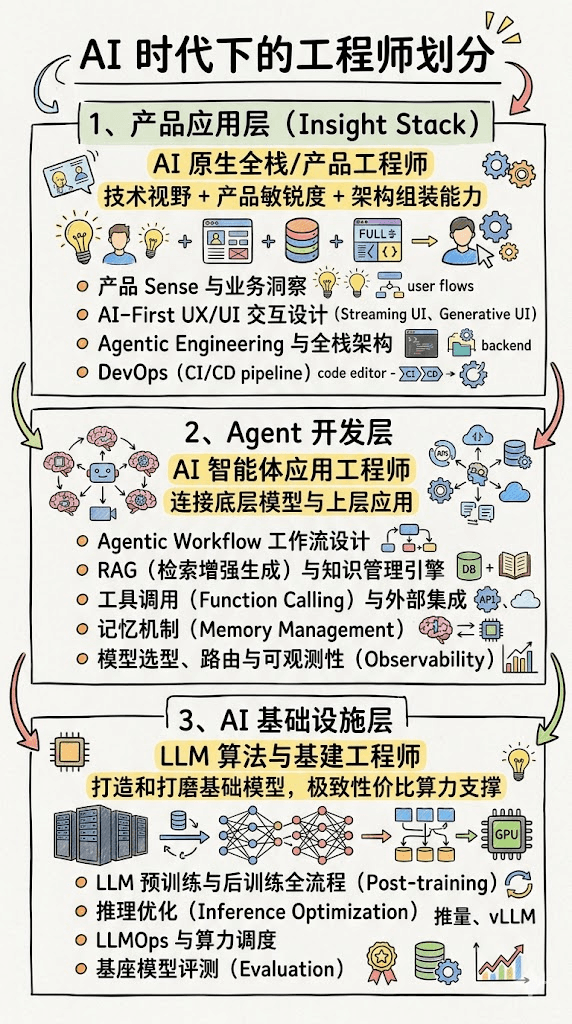
行业的演进给出了答案:开发者的角色正在经历一次彻底的重构。我们正在从“代码的编写者”转变为“系统的架构者”与“AI 智能体的指挥官”。结合当下的工业界实践,我们可以将 AI 时代的工程师图谱清晰地划分为三大核心圈层:产品应用层、Agent 开发层与 AI 基础设施层。
1. 产品应用层(Insight Stack):走向“超级个体”的 AI 原生全栈
核心壁垒:技术视野 + 产品敏锐度 + 极速的架构组装能力,能够单枪匹马或带领极小团队,将一个灵感迅速转化为高可用产品。
在 AI 极大地降低了代码编写门槛的今天,“决定做什么”和“如何利用 AI 构建系统”的价值,已经逐渐超越了“纯手工敲击代码”的价值。这或许是传统前端、后端开发者转型最顺滑、也最能释放巨大商业价值的一层。
在这一层,“全栈工程师”的定义被重新改写为“产品工程师(Product Engineer)”。技术栈不再仅仅是前端框架和数据库,而是包含了“产品 Sense”与“商业洞察”的 Insight Stack。全栈工程师也正在进化为“超级个体”或“产品工程师(Product Engineer)”。问题发现 -> 创意沉淀 -> AI 辅助技术方案 -> AI 驱动代码生成这一闭环,正是当前最高效的独立开发或小团队敏捷开发范式。
1.1 产品 Sense 与业务洞察
过去,工程师往往是被动接收 PRD。而在 AI 时代,技术门槛的降低意味着工程师可以随时将生活和工作中的“灵感碎片”与“痛点捕获”转化为产品创意。我们需要具备极其敏锐的 AI 边界认知,明确知道哪些场景适合用传统的 CRUD 解决,哪些必须交由 LLM 去处理模糊与非确定性。
在产品应用层,我们还需要具备数据飞轮意识,注重在应用层设计埋点,收集用户的交互与纠错数据,为后续的 Agentic workflow 优化或模型微调提供高质量数据源。
1.2 Agentic Engineering(智能体工程)
这是一种全新的开发范式,开发者不再逐行手敲代码,而是通过撰写严谨的 Spec、利用 TDD(测试驱动开发)和 Lint 强约束,去“驱动”和“管理” AI 编程助手(如 Claude Code、Cursor),全栈基础设施的范畴也扩展到了跨端轻量化应用(例如利用前端技术栈快速构建高价值的浏览器插件)。
| 能力维度 | 具体要求 |
|---|---|
| 规划、设计与迭代能力 | • 能够快速响应业务需求,规划产品功能,完成技术架构的调研、选型与整体设计。 • 能借助 AI 进行前端视图层、Node.js 后端核心数据流、业务流程的顶层设计。 • 不但能单枪匹马或带领极小团队中的人,还懂得领导、管理 AI 数字员工。 |
| AI 驱动编程 | 基于 Spec、TDD、Hooks(Lint 检查)等强约束机制,驱动 Claude Code / Copilot 等工具生成高规范度代码。 |
| 全栈基础设施 | 熟练掌握传统架构体系(数据库选型、Redis、微服务、消息队列),以及跨端/轻量化形态(如 Chrome 插件生态)的工程搭建。 |
| DevOps | 现代化的自动化部署、CI/CD 流水线搭建与运维。 |
1.3 AI-First 的交互哲学
AI 应用的体验与传统软件截然不同。为了对抗大模型的延迟与幻觉,工程师必须掌握流式渲染(Streaming UI)、生成式 UI(Generative UI)等新一代交互模式,用优雅的工程设计兜底 AI 的不确定性。
- 流式渲染(Streaming UI):优化大模型响应的等待体验。
- 生成式交互(Generative UI):在前端框架(如 React / Next.js)中,根据 AI 返回的结构化状态实时渲染出最合适的交互组件,而非死板的对话框。
- 容错与兜底机制:优雅处理大模型幻觉(Hallucination),降低用户的挫败感。
2. Agent 开发层:构建连接物理世界的数字中枢
核心壁垒:标准化模块组装 + 复杂 Agentic Workflow 编排 + 严谨的评测体系,这一层负责为 AI 赋予记忆、手脚和专业领域的知识,是连接“底层模型大脑”与“上层应用交互”的核心枢纽。
如果说大模型是大脑,那么 Agent 工程师就是为这个大脑装上“四肢”、“记忆”和“专业工具”的人,这是一个正在爆发的新兴领域,也是实现 AI 业务落地的核心枢纽。
2.1 Agentic Workflow 设计
| 能力维度 | 具体要求 |
|---|---|
| 任务拆解与路由 | 基于 CoT(思维链)等技术工程的任务拆解与路由机制,针对不同复杂度的工作流设计稳健的多 Agent 协作与分发机制。 |
| 设计模式与编排 | 熟练应用 ReAct、Plan-and-Execute 等智能体设计模式,针对不同的业务场景(如信息爬取、长文总结过滤等自动化处理),设计稳健的多 Agent 协作与路由流。 |
| 主流 Agent 框架的核心机制与实战落地 | 熟悉并掌握如 Claude Agent SDK、LangChain、AutoGen 等主流 Agent 框架的核心机制,能够在实际项目中灵活应用,解决复杂的业务场景。 |
2.2 记忆机制(Memory Management)
要让 Agent 变得“好用”,必须解决上下文遗忘和知识幻觉的问题。这就要求工程师深谙长期记忆/短期记忆的协同管理,以及复杂文档的切块(Chunking)、向量化(Embedding)和混合检索(Hybrid Search)技术。
- 短期记忆:精准控制 Context Window,进行 Prompt 截断与摘要,即上下文工程能力。
- 长期记忆:基于图数据库或向量库,持久化存储用户画像与历史交互状态。
2.3 技能的插件化(Agent Skill)
Agent Skill 是由 Anthropic 提出并推动的一种开放式标准,旨在将特定领域的知识、工作流、指令和脚本打包封装成的标准化、模块化资源包,让 AI Agent 按需动态加载这些技能,实现从通用助手向特定任务专家(如代码审计、法律文件分析)的无缝转变。
- 结构化封装:以目录形式组织(如含
SKILL.md的文件夹),包含详细的执行规则。 - 渐进披露 & 按需调用:Agent 仅在处理相关任务时动态激活这些能力,无需每次提示都包含所有技能。
- 可重用与组合:技能可多次重复使用,或多个技能组合处理复杂流程。
无论是长文抓取、摘要提取还是打标签,都可以被封装为独立的 Skill,在复杂的 Workflow 中被 Agent 动态挂载,即插即用,在构建特定场景的 Agent(例如专注于技术资讯处理的知识管理助手)时,能够像搭积木一样,根据当前任务的上下文动态加载所需的 Skills,从而大幅提升 Agent 的泛化能力和开发效率。
2.4 从硬编码到标准协议与上下文连接
随着 MCP(Model Context Protocol)等标准化协议的成熟,Agent 开发正在摆脱杂乱的胶水代码。我们可以利用熟悉的后端生态(如 Node.js)构建 MCP Server,让 AI 安全、统一地读取外部 API 或是企业内部知识库,打破信息孤岛。
- 统一数据接入层:不再需要为每一个数据源(如 Notion、本地文件系统、特定的研发工具或外部 API)手写杂乱的胶水代码。通过实现和接入 MCP Server,为大模型提供一套标准化的双向通信协议。
- 跨生态与端侧集成:能够利用 Node.js 等熟悉的后端生态快速构建 MCP 服务,让大模型统一、安全地读取多源上下文。这对于开发跨端的 AI 应用(如在浏览器插件中打破沙盒限制,直接与本地或云端知识库联动)至关重要。
2.5 模型选型、路由与可观测性
- 动态 API 路由:在成本与性能之间取舍,灵活调度国内外大模型(Claude、Gemini、GPT-4,以及国内的 DeepSeek、GLM、MiniMax、Qwen等)。
- Agent 监控:构建测试集(Eval),监控链路执行过程(Tracing),分析 Token 消耗与步骤延迟。
2.6 EDD(评估驱动开发)重塑工程质量
在 Agent 开发中,大模型的输出具有非确定性,如果说开发 Agent 只是完成了从 0 到 1 的“能用”,那么构建完善的评测体系,就是解决从 1 到 100 的“好用”与“敢用”的核心壁垒。成熟的 Agent 工程师必须建立系统的评测与监控体系(Observability),通过构建黄金测试集(Golden Dataset)、引入 LLM-as-a-Judge,以及精确到 Token 级的链路追踪(Tracing),将“感觉不错”的玄学转化为可量化的工程指标。
| 能力维度 | 具体要求 |
|---|---|
| 自动化评测驱动 (EDD) | 摒弃"肉眼看效果"的游击战,建立特定场景的 Golden Dataset(基准测试集),熟练引入 Promptfoo、Ragas 等评估框架,将评测无缝融入 CI/CD 流水线。 |
| 多维指标体系设计 | 针对具体任务(如长文总结、内容归类),设计并量化诸如事实一致性 (Faithfulness)、答案相关性 (Answer Relevance)、幻觉率 (Hallucination Rate) 等核心指标。 |
| LLM-as-a-Judge 与人工对齐 | 使用强模型(如 Claude 4.6/GPT)来批量自动评测弱模型或 Agent 的输出质量,并在关键节点结合 HITL(Human-in-the-loop,人机协同)进行人工微调与对齐。 |
| 链路追踪与归因 (Tracing) | 面对多 Agent 协作或复杂的 RAG 链路,熟练使用 LangSmith、Langfuse 等可观测性工具,记录每一次工具调用、Prompt 组装耗时和 Token 消耗,精准定位 Bad Case 的根因。 |
3. AI 基础设施层:算力与模型的重工业底座
核心壁垒:深厚的底层算法素养 + 极致的性能压榨 + 大规模分布式系统经验。这一层是 AI 时代的“重工业”底座,负责打造和打磨基础模型,并提供极致性价比的算力支撑。
技术工程背景的工程师可暂时只关注于模型预备训练、后训练、推理等放面的原理与流程,以及如何在大规模分布式系统上高效部署和运行这些模型,而无需深入理解底层的分布式系统和计算架构。
如果前两层是造车和开车的,这一层就是修路和提炼石油的。这属于 AI 的“重工业”,门槛极高,主要由具备深厚算法背景和底层工程能力的顶级大厂或 AI Native 独角兽主导。
| 能力维度 | 具体要求 |
|---|---|
| 模型精炼与对齐 | 随着开源基座模型的强大,预训练已不再是唯一解。后训练(Post-training)阶段的变得至关重要,通过 RL(强化学习)、SFT(监督微调)、RLHF/DPO(人类偏好对齐),将通用模型打磨成特定领域(如代码生成、逻辑推理)的专家。 |
| 极致的推理优化 | 随着模型越大,成本越高。熟练掌握 vLLM 等高性能推理框架,运用量化技术(如 FP8/INT4)、KV Cache 优化(如 PagedAttention),在不牺牲精度的前提下榨干每一滴 GPU 算力。 |
| LLMOps 与算力调度 | 在万卡级别的 GPU 集群上,处理节点故障、实现资源负载均衡和容灾恢复,保障极其昂贵的算力资源不被浪费。 |
4. 找准自己的生态位
面对这股重塑整个行业的洪流,焦虑是本能,但进阶才是解药。
对于绝大多数有着丰富 Web 开发经验(无论是精通前端交互,还是深谙 Node.js/Golang/Java 等后端架构)的工程师而言,“产品应用层”和“Agent 开发层”不仅是最具性价比的切入点,更是能够最大化杠杆原有技能的沃土。
我们不应该将自己局限在“写代码的机器”这一狭窄定义中。尝试用产品 Sense 发现问题,用 AI 编程工具快速实现 MVP,用标准的 Agent skills、MCP 协议和高阶 Agentic workflow 设计赋予应用专业深度。
AI 不会淘汰开发者,只会淘汰那些拒绝使用 AI 来放大自身产品价值的开发者。在技术通缩的时代,唯有洞察力和对业务流的把控力,才能迎来真正的价值膨胀。